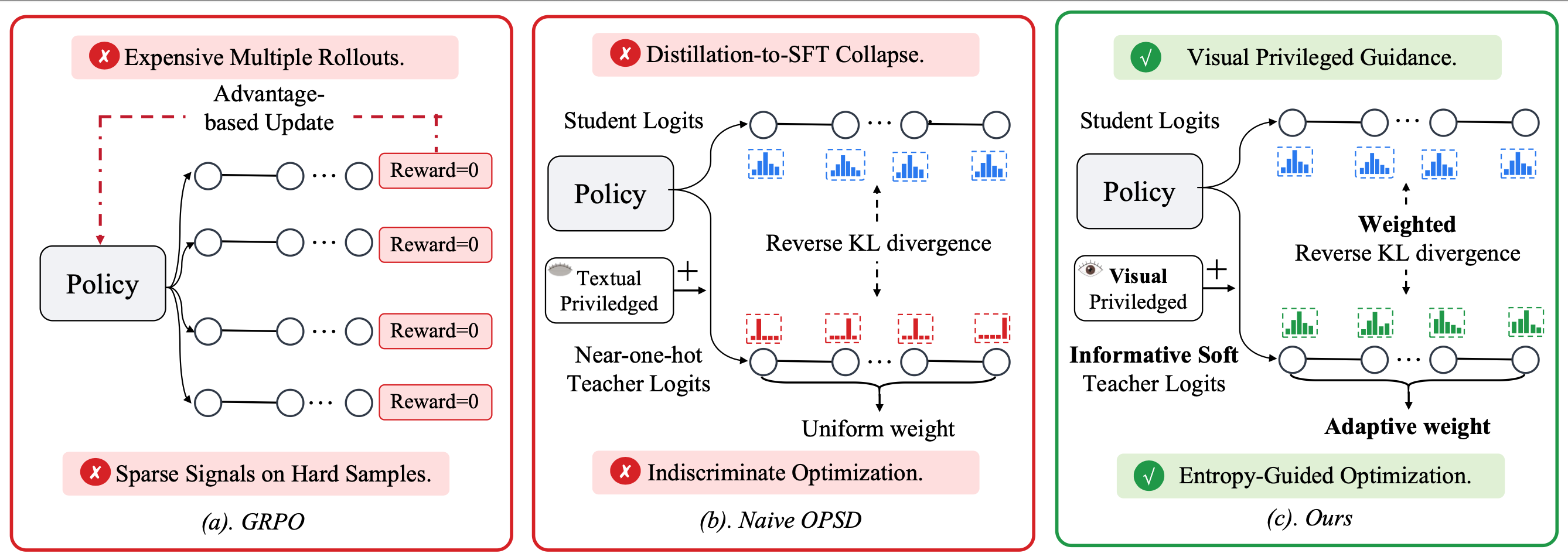
Method Overview
GUI-SD consists of two complementary components: (a) Teacher Privileged Guidance — the teacher receives a visually enriched privileged context (drawn bounding box + Gaussian soft-mask), while the student receives the original image. Both share the same policy weights. (b) Entropy-Guided Optimization — computes reverse KL divergence between teacher and student logits at each token position, weighted by positional credit assignment (higher weight for high-order digits) and entropy-gated supervision (higher weight for low-entropy, high-confidence teacher predictions).
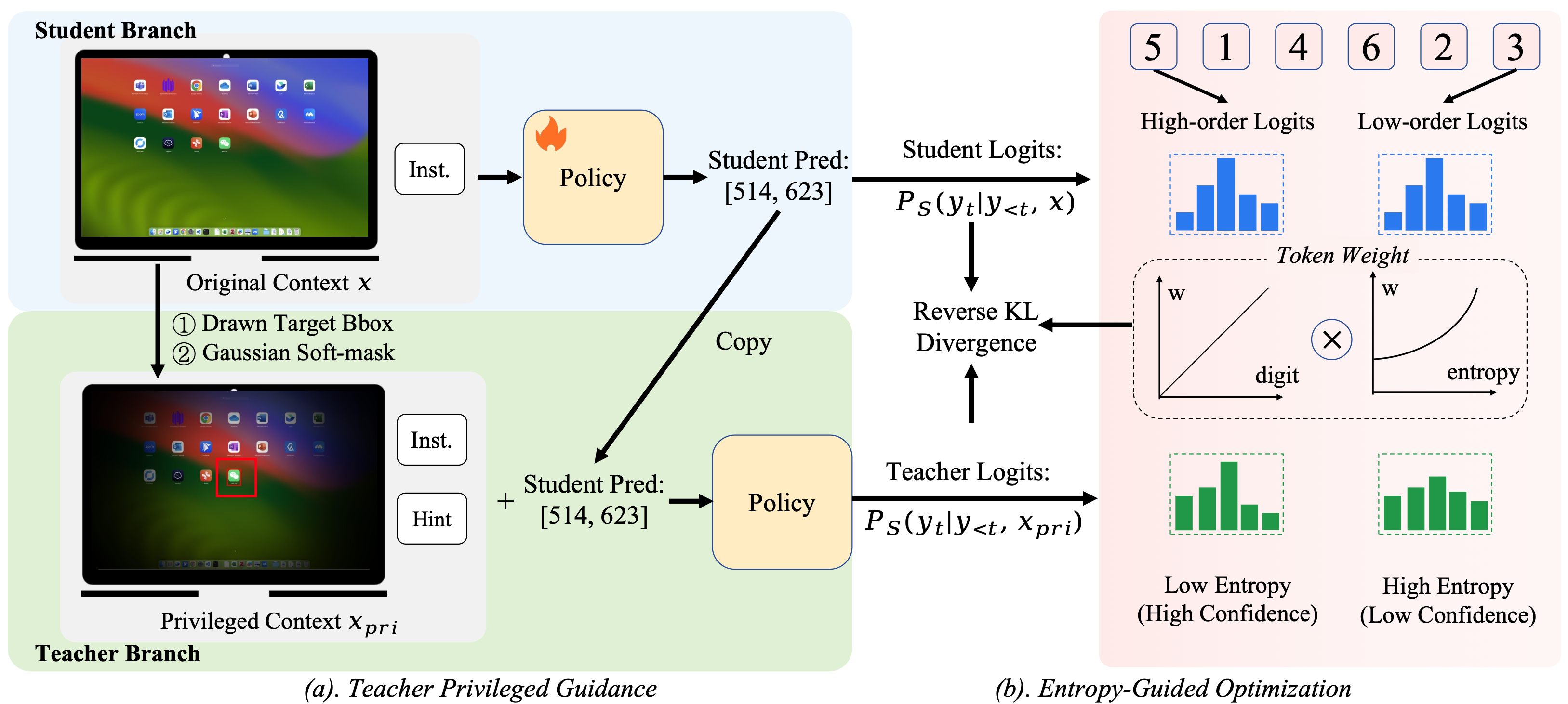
Figure 3. Overview of the GUI-SD framework. (a) The teacher takes a privileged context xpri, which augments the student's original input x with visual cues and a hint prompt, to produce richer soft labels for guiding the student. (b) The training objective is a weighted KL divergence, where w(t) prioritizes high-order tokens via positional credit and filters unreliable supervision via entropy gating on teacher confidence.